








前言
由于最近Computer Vision作业需要用到Adversarial Attack,于是乎来复习一下,顺便implement一下。
原理部分请见:[人工智能] 对抗攻击(Adversarial Attack)原理
正文
1. 背景
1.1. 事故
这一段背景来自《对抗图像和攻击在Keras和TensorFlow上的实现》,觉得写得很不错,于是引用过来,以下是原话:
试想下从现在起的二十年后。现在路上所有的车辆都是利用人工智能、深度学习和计算机视觉来驱动的无人驾驶交通工具。每一次转弯、车道转换、加速和刹车都是由深度神经网络来提供技术支持。现在,想象自己在高速路上,你正坐在“驾驶室(当车自主行驶时,驾驶室还能被称为‘驾驶室’吗?)”里,你的妻子坐在副驾上,你的孩子们坐在后座。
朝前看,你看到一张巨大的贴纸正在车辆所行驶的车道上,这看上去对车的前进毫无影响。看上去这像是一张受欢迎的大幅涂鸦艺术版画,可能是几个高中生开玩笑把它放在这里,或者他们只是为了完成某个大冒险游戏。

图一:执行一次对抗攻击需要一张输入图像(左),故意用一个噪声向量来扰乱它(中),迫使神经网络对输入图像进行错误分类,最后得到一个错误的分类结果,很可能会出现一次严重的后果(右)。
一瞬间,你的汽车突然急刹车,然后立即变道,因为放在路上的那张贴画可能印的是行人、动物或者另一辆汽车。你在车里被猛推了一下,感到颈部似乎受了伤。你的妻子尖叫着,孩子们的零食在后座上蹦了起来,弹在挡风玻璃上后洒在中控台上。你和你的家人都很安全,但所经历的这一切看上去不能再糟糕了。
发生了什么?为什么你的自动驾驶车辆会做出这样的反应?是不是车内的某段代码或者某个软件存在奇怪的“bug”?
答案就是,为车辆视觉组件提供技术支持的深度神经网络看到了一张对抗图像。对抗图像是指:含有蓄意或故意干扰像素来混淆或欺骗模型的图像。 但与此同时,这张图像对于人类来说看上去是无害且无恶意的。这些图像导致深度神经网络故意做出错误的预测。对抗图像在某种方式上去干扰模型,导致它们无法做出正确的分类。事实上,人类通过视觉可能无法区分正常图片和对抗攻击的图片——本质上,这两张图片对于肉眼来说是相同的。
1.2. 入侵
另外一些后果没有那么严重的示例,例如一群黑客识别了一个谷歌用于给Gmail过滤垃圾邮件的模型,或者识别了一个Facebook自动检测色情内容的NSFW(不适合上班时间浏览)过滤器模型。
如果这些黑客想要绕过Gmail垃圾邮件过滤器来让用户受到资源过载攻击,或者绕过Facebook的NSFW过滤器来上传大量的色情内容,理论上讲他们是可以做到的。
这些都是对抗攻击中造成轻微后果的示例。
关于到对抗攻击带有严重后果的剧本可以包括黑客恐怖分子识别了全世界自动驾驶汽车所使用的深度神经网络(试想一下如果特斯拉垄断了市场,成为世界唯一自动驾驶汽车生产商)。
对抗图片有可能被有战略性地摆放在车道或公路上,造成连环车祸、财产损失或车内乘客的受伤甚至死亡。
只有你的想象力,对已知模型的了解程度以及对模型的使用程度是对抗攻击的天花板。
2. 回顾
以下稍微回归一下,攻击的两种种类,和我们攻击所需要的限制/条件:
对抗攻击(Adversarial Attack):主要分为白盒攻击和黑盒攻击
- 白盒攻击:指的是模型的参数与结构对我们而言是透明的,我们可以直接对模型进行查看,并且设计出攻击策略。
- 黑盒攻击:然而黑盒指的是,模型并没有被公开,我们无法知道模型的参数与结构,大多数情况下我们需要对利用其输入和预测的输出,进行模拟,并且希望训练出一个类似的模型。
攻击条件:无论是对于白盒攻击还是黑盒攻击而言,其都必须满足两个 条件
- 在原始数据加入了噪音之后,预测数据必须与真实数据尽可能远,如果是定向攻击的话(target),预测数据还必须与预定的假数据尽可能近。
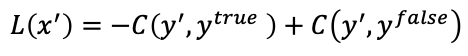
- 加入的噪音必须早一定范围内,尽可能使人类无法分辨出与原数据的区别。
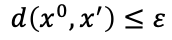
3. 实现
3.1. 数据 & 模型导入
这里我们用的数据和模型都来自《[人工智能] 试着用卷积神经网络(CNN:Convolutional Neural Networks)教电脑认识塔菲和东哥》
其中分别对于塔菲和东哥,测试集都有着如下的置信率:
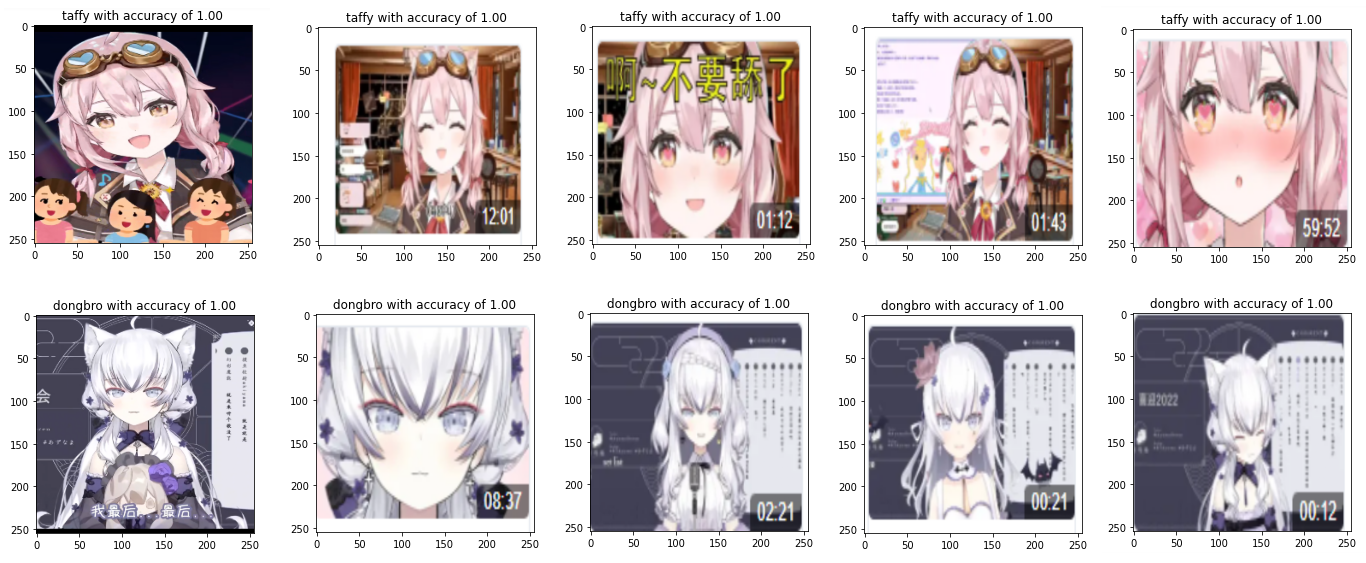
可以看出来模型的识别略是相当高的。我们准备对其进行对抗攻击。
3.2. Helper
def generate_delta(baseImage):
return tf.Variable(tf.zeros_like(baseImage), trainable=True)
def preprocess_data(base_image, delta):
return base_image + delta
def clip_eps(tensor, eps):
return tf.clip_by_value(tensor,clip_value_min=-eps, clip_value_max=eps)
这里我们定义了3个helper函数:
generate_delta是用来生成noise杂讯的。preprocess_data是用来处理 原图像 和 noise杂讯的关系的,这里我们直接用的就是pair-wise叠加clip_eps是用来限定扰动只能在一定距离范围内,人眼不能识别出来。
3.3. 非定向攻击
def generate_adversaries_non_target(model, baseImage, delta, classIdx, cceLoss, optimizer, steps=50):
for step in range(steps):
with tf.GradientTape() as tape:
tape.watch(delta)
adversary = preprocess_data(baseImage, delta)
predictions = model(adversary, training=False)
loss = -cceLoss(predictions, tf.convert_to_tensor([classIdx]))
if step % 5 == 0:
print("step:%d, loss:%.4f" % (step, loss))
gradients = tape.gradient(loss, delta)
optimizer.apply_gradients([(gradients, delta)])
delta.assign_add(clip_eps(delta, eps=EPS))
return delta
这是我们的核心代码,参数说明:
model为模型baseImage为原图像delta为添加的noise/杂讯/扰动classIdx为原图像的真实labelscceLoss为使用的loss function,我们这个地方使用的是CategoricalCrossentropy()optimizer为使用的optimization function,我们这里使用的是Adam()steps为总共训练的个数,这里我们默认是50次,但是实际设定是500次,最终稳定是285次。
核心代码说明:
tf.GradientTape()说明我们用GradientTape来记录梯度watch.tape()意味在tape上调用.watch方法,指出noise/杂讯/扰动向量是可以用来追踪更新的preprocess_data对原图像和delta进行处理,创建出我们最终给model的输入input向量model(adversary, training=False)得到我们adversary数据的输出结果loss = -cceLoss()计算Loss,我们尽可能让loss差距越大越好,因为非定向攻击就是为了让原模型不能输出正确的值。公式:
tape.gradient()为了计算gradientsoptimizer.apply_gradients()应用gradient到delta上delta.assign_add()用于截取超出 [-EPS,EPS] 范围外的值。
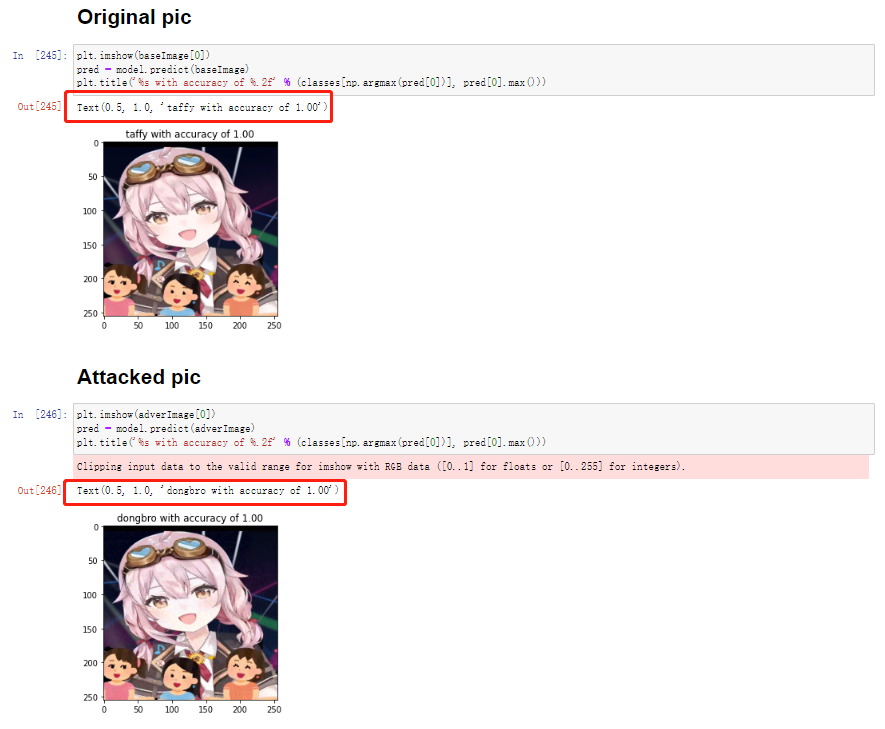
最终非定向攻击的结果如下:
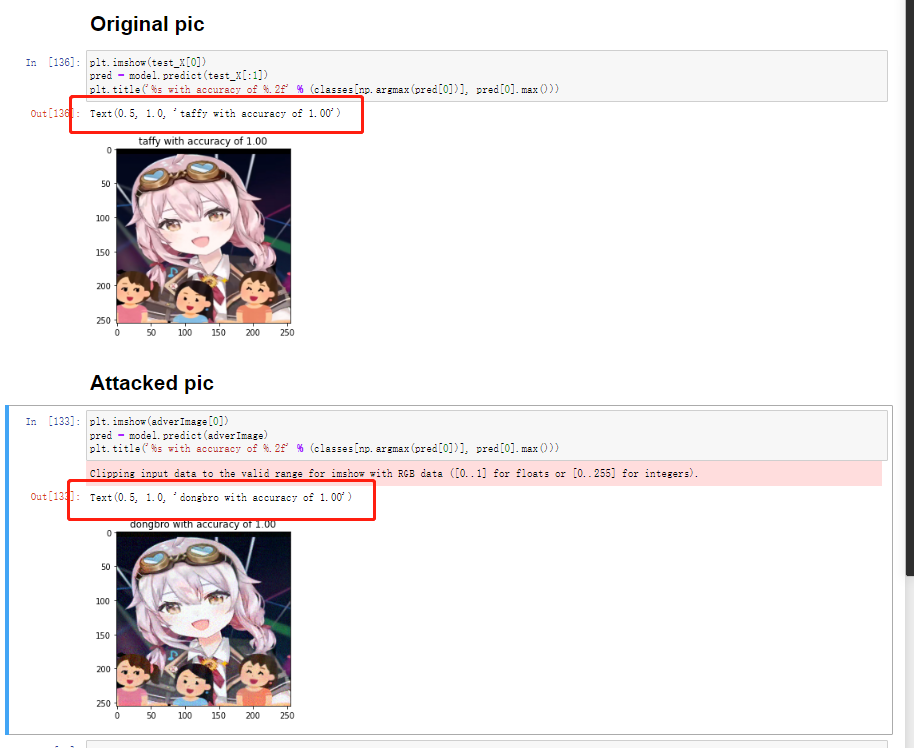
可以很明显的看到,本来模型100%确认是taffy的图像,现在被更改成了模型100%确认是dongbro的图像。然而,这个完全是我们adversarial attack的结果。因为我们东哥的数据集其实与这个完全没有任何的关系:

3.4. 定向攻击
定向攻击和非定向攻击的唯一差别其实就在于Loss Function:
- 对于非定向攻击而言,只有第一部分的y'和y^
- 对于定向攻击而言,既有第一部分的y'和ytrue 也有第二部分的y'和yfalse;而且yfalse就是我们的希望model学习的错误的label
对于定向攻击而言,其核心代码为:
def generate_adversaries_target(model, baseImage, delta, classIdx, targetIdx, cceLoss, optimizer, steps=50):
for step in range(steps):
with tf.GradientTape() as tape:
tape.watch(delta)
adversary = preprocess_data(baseImage, delta)
#prediction = model.predict(np.array([adversary]))
#loss, acc = model.evaluate(np.array([adversary]), np.array([classIdx]))
predictions = model(adversary, training=False)
loss = -cceLoss(predictions, tf.convert_to_tensor([classIdx])) +cceLoss(predictions, tf.convert_to_tensor([targetIdx]))
if step % 5 == 0:
print("step:%d, loss:%.4f" % (step, loss))
gradients = tape.gradient(loss, delta)
optimizer.apply_gradients([(gradients, delta)])
delta.assign_add(clip_eps(delta, eps=EPS))
return delta
由于之前只有2个classes,所以不好看出来差别,为了看出来差别,这个地方又引入了狗妈(神乐七奈)的数据库:
-5a135b0b9c8247428de807d809dc3209.png)
对于模型的参数部分,相比于非定向攻击而言,定向攻击多了一个参数:
targetIdx,这个是我们定向攻击的label,模型最终会将图片识别为targetIdx这个class,而不是原本的classIdx这个原本的class。
对于核心代码而言,仅仅的差别在于loss:
loss = -cceLoss(predictions, tf.convert_to_tensor([classIdx])) +cceLoss(predictions, tf.convert_to_tensor([targetIdx])),而不再是简简单单的loss = -cceLoss(predictions, tf.convert_to_tensor([classIdx])),因为这个地方不仅仅考虑了要距离真实值远,还要考虑距离虚假值要足够的近。
最终非定向攻击的结果如下:
可以很明显的看到,本来模型100%确认是taffy的图像,现在被更改成了模型100%确认是dongbro的图像。而且并没有被识别成kaguranana(狗妈)的图像。
为了确定我们真的是有noise/delta/干扰/杂讯的,我们将杂讯放大了50倍:
-dcf56b51238d430a8c2d7f0a8735cc87.png)
证明我们确实是有noise/delta/干扰/杂讯的~!。
4. 数据库
4.1. 训练集 - taffy(永雏塔菲)
-4b4fe14606f745fb9c6490e9491db4d5.png)
4.2. 训练集 - dongbro(东雪莲)
4.3. 训练集 - kaguranana(神乐七奈)
4.4. 测试集 - taffy(永雏塔菲)
-49881a036b3148628b2c4f526e5beaa7.png)
4.5. 测试集 - dongbro(东雪莲)
-158a59dc40994a859e093cd9e3a05c74.png)
4.6. 测试集- kaguranana(神乐七奈)
-0bf286c8630b4873a8b898de720ffa54.png)
总结
其实蛮可怕的,如果这样的数据真的被制作出来,甚至如果被放进一些baseline,benchmark的数据集里面,那将大幅度感染之后训练在含有这样的数据的数据集上的神经网络。
吓人┌(。Д。)┐
所以安全,还是很重要的!
参考
[1] 白盒攻击算法
[2] 对抗图像和攻击在Keras和TensorFlow上的实现
Q.E.D.