








前言
最近Computer Vision的作业需要用到Adversarial Attack,刚好对这一块进行复习一下。
顺便之前开了一篇taffy和东哥的坑,于是乎就以那个作为例子来做一下吧。但是稍微扩展一下,大概数据集会有3个class,taffy、东哥和嘉然。
为了多水几篇,训练模型和实现部分,嘻嘻,就放在,下一篇吧。喵喵~!
正文
1. 概要
攻防定义:在日常的神经网络开发中,我们通常重点在于模型的performance,他的准确性或者对环境的robustness。但是对于某些领域,人脸识别等安全领域,模型攻击也会是需要考虑的一种内容。模型攻击指的是,我们可以通过对数据加入某种噪声后,使模型能够错误的识别成我们想要其识别的类别。
对抗攻击(Adversarial Attack):主要分为白盒攻击和黑盒攻击
- 白盒攻击:指的是模型的参数与结构对我们而言是透明的,我们可以直接对模型进行查看,并且设计出攻击策略。
- 黑盒攻击:然而黑盒指的是,模型并没有被公开,我们无法知道模型的参数与结构,大多数情况下我们需要对利用其输入和预测的输出,进行模拟,并且希望训练出一个类似的模型。
攻击条件:无论是对于白盒攻击还是黑盒攻击而言,其都必须满足两个 条件
- 在原始数据加入了噪音之后,预测数据必须与真实数据尽可能远,如果是定向攻击的话(target),预测数据还必须与预定的假数据尽可能近。
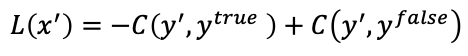
- 加入的噪音必须早一定范围内,尽可能使人类无法分辨出与原数据的区别。
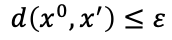
噪音距离定义:
- L2距离:假样本与真样本的均方差
-82c2469c6b424441ae7339fa5ca8b398.png)
- 最大距离:假样本与真样本,差别最大的点
-15d64732407343f8878a6e0d7b2f0538.png)
定向与非定向攻击:
- 定向攻击:指的是让模型输出指定的假label
- 非定向攻击:指的是只要让模型输出不是真实的label即可
模型攻击场景:大部分领域都存在模型攻击的安全性的问题,在实际场景中,例如人脸识别,李宏毅老师视频中指出,有paper做了一副能够实现攻击模型的眼睛,带上眼镜之后能够将戴上眼镜的人,直接识别为一名女明星。毫无疑问,这会对业务的安全性造成十分严重的影响。

2. 模型攻击
2.1. 白盒攻击
白盒攻击指的是在知道模型结构和参数的情况下,设计方法对其进行攻击。最常用且最简单的方法为FGSM,快速梯度下降。在白盒攻击中,我们的神经网络参数和结构是已知的,我们要调整的样本输入x,通过梯度下降来找到最合适的样本x。
白盒模型中常用的方法为:
- FGSM
- Basic iterative method
- L-BFGS
- Deepfool
- JSMA
- C&W
- Elastic Net Attack
- Spatially Transformed
- One Pixel Attack
2.2. 黑盒攻击
黑盒攻击方法是我们对未知的模型结构和参数进行攻击。通用的方法是我们利用我们的输入,得到模型的输出,然后利用输入和模型现有的输出,去训练一个自己的模型,然后对这个模型进行白盒攻击。利用此方法训练出来的模拟模型,一般来说效果也不错。
3. 模型防御
3.1. 被动防御
被动防御是指不修改原始模型的情况下,我们对模型增加filter,例如smoothing,来对输入进行处理,来防止模型攻击。这样的方法优点是很简单,但是缺点是一旦攻击者知道了filter的类型,就相当于只是在模型前面加多了一层layer而已。为了防止这种情况,我们可以使用Random filter,这样我们自己都不知道filter是什么,但是针对这种情况,universal attack也许也可以针对这种情况。
3.2. 主动防御
主动防御的思想,是指我们先对模型自己进行检测,找出模型的limitation。然后把他们加入到训练数据当中,重新训练模型。从而使得我们即使在这种假样本上,也能predict出正确的方法。这样的方法其实有点类似数据强化(Data Augmentation)。
总结
- 对抗攻击分为:白盒攻击和黑盒攻击
- 攻击能分为定向(Target)与非定向(Non-Target)
- 攻击的Constraint:距离真实的值足够的远 & 人类无法识别假的与真的数据
- 模型防御分为:被动防御和主动防御
参考
[1] 机器学习8 -- 模型攻防(model attack & model defense)
[2] 白盒攻击算法
[3] 初探对抗攻击——黑盒攻击&白盒攻击
[4] 【機器學習2021】來自人類的惡意攻擊 (Adversarial Attack) (上) – 基本概念
[5] 【機器學習2021】來自人類的惡意攻擊 (Adversarial Attack) (下) – 類神經網路能否躲過人類深不見底的惡意?
[6] 李宏毅——对抗模型 attack and defence
[7] 李宏毅机器学习笔记——14. Attack ML Models and Defense(机器学习模型的攻击与防御)
Q.E.D.