








前言
Cart Pole是一个很经典的Reinforcement Learning问题,我们这里就言简意赅了,该问题就是一个小车上面有一个平衡木,要让AI去学习如何让这个平衡木不倒下。
我们这里之所以称之为Deep Reinforcement Learning是因为我们加入了Neural Network神经网络来进行计算,对输入states -> actions, next_states 这样的Q-values进行计算。
我们这里依旧参考的是《Reinforcement Learning - Developing Intelligent Agents》,问题来自于Gym的《Cart Pole - Gym Documentation》。
正文
1. 思路
具体思路来自于《Reinforcement Learning - Developing Intelligent Agents》,我们首先祭出原版的英文思路,避免中文翻译的歧义:
- Initialize replay memory capacity
- Initialize the policy network with random weights
- Clone the policy network, and call it the target networks
- For each episode:
- Initialize the starting state
- For each time step:
- Select an action
- Via exploration or exploitation
- Execute selected action in an emulator
- Observe reward and next state
- Store experience in replay memory
- Sample random batch from replay memory
- Preprocesses state from batch
- Pass batch of preprocessed states to policy network
- Calculate loss between output Q-values and target Q-values
- Requires a pass to the target network for the next state
- Gradient descent updates weights in the policy network to minimize loss
- After x time steps, weights in the target network are updated to the weights in the policy network
- Select an action
下面是中文版:
- 首先我们需要一个Replay Memory,因为我们的dataset是实时的,并不是固定的,所以我们需要一个Replay Memory去记录我们新的dataset,然后舍去我们老旧的dataset
- 我们的Policy Network,需要被初始化
- 其次是我们还创建了一个Network 叫做Target Network,它的作用是,我们在Bellman Equation里面有一步是需要涉及next_state的reward,但是如果我们用Policy Network来计算next_state的reward的话,Policy Network会在next_state改变,这样的话我们的计算会有问题(具体什么问题其实我也没有搞清楚,有懂的亲们可以回复一下,求告诉。0.0。),所以我们打算创建一个固定的Target Network,然后过一段episodes之后再更新这个Target Network。
- 然后是在每一个episode里面的动作
- 初始化
- 对于每一个episode里面的每一个time step
- 和我们之前讲的一样,我们需要选择一个行为
- 这个行为可以是exploration或者exploitation的
- 执行这个行为在模拟器中
- 得到reward 和 next state
- 放入replay memory中
- 当reply memory中的size >= batch size的时候,我们就可以从里面取样了,如果不大于则暂时不取样
- 数据预处理
- 将预处理的batch 数据放入policy network中准备进行训练
- 计算Q-value 和 target Q-value(Target Network中得到)的损失函数
- 需要一个从target network中得到Q-value的函数
- 通过梯度下降更新policy network
- 记住在x时间之后,需要更新我们的target network,否则会和policy network相差太远
- 和我们之前讲的一样,我们需要选择一个行为
思路清楚过后,便是Python源码了
2. Python源码
2.1 Import 与 版本控制
源码设计的包
# Import packages
from collections import namedtuple
from itertools import count
from PIL import Image
import numpy as np
import pygame
import random
import math
import time
import gym
import sys
# Drawing
import matplotlib.pyplot as plt
import matplotlib
is_ipython = 'inline' in matplotlib.get_backend()
if is_ipython: from IPython import display
# PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as T
版本控制
print("Python Version:", sys.version_info)
print("numpy:", np.__version__)
print("gym:", gym.__version__)
print("pygame:", pygame.__version__)
print("matplotlib:", matplotlib.__version__)
print("PyTorch:", torch.__version__)
Python Version: sys.version_info(major=3, minor=8, micro=17, releaselevel='final', serial=0)
numpy: 1.24.4
gym: 0.26.2
pygame: 2.5.0
matplotlib: 3.7.2
PyTorch: 2.0.1
2.2 DQN神经网络
class DQN(nn.Module):
def __init__(self, img_height, img_width):
super().__init__()
self.fc1 = nn.Linear(in_features=img_height*img_width*3, out_features=24)
self.fc2 = nn.Linear(in_features=24, out_features=32)
self.out = nn.Linear(in_features=32, out_features=2)
def forward(self, t):
# because the input size of self.fc1 is (1,x), which is one dimension
t = t.flatten(start_dim=1)
t = F.relu(self.fc1(t))
t = F.relu(self.fc2(t))
t = self.out(t)
return t
2.3 实体Entity
自定义数据类型Experience,利于training:
# Python function to create tuple with name field
Experience = namedtuple(
'Experience',
('state', 'action', 'next_state', 'reward')
)
Replay Memory,存放和管理training dataset:
class ReplayMemory():
def __init__(self, capacity):
self.capacity = capacity
self.memory = []
self.push_count = 0
def push(self, experience):
if len(self.memory) < self.capacity:
self.memory.append(experience)
else:
self.memory[self.push_count % self.capacity] = experience
self.push_count += 1
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def can_provide_sample(self, batch_size):
return len(self.memory) >= batch_size
Epsilon Greedy Strategy,用来改变Exploration rate的函数,决定下一步action是exploration 还是 exploitation:
class EpsilonGreedyStrategy():
def __init__(self, start, end, decay):
self.start = start
self.end = end
self.decay = decay
def get_exploration_rate(self, current_step):
return self.end + (self.start - self.end) * \
math.exp(-1. * current_step * self.decay)
Reinforcement Learning Agent,训练的实体,也就是我们的cart pole:
class Agent():
def __init__(self, strategy, num_actions, device):
self.current_step = 0
self.strategy = strategy
self.num_actions = num_actions
self.device = device
def select_actions(self, state, policy_net):
rate = strategy.get_exploration_rate(self.current_step)
self.current_step += 1
if rate > random.random():
action = random.randrange(self.num_actions)
return torch.tensor([action]).to(device) # explore
else:
with torch.no_grad(): # turn off gradient tracking, in this case we just inference not training
return policy_net(state).argmax(dim=1).to(device) # exploit
Cart-Pole Environment Manager,控制我们的环境:
class CartPoleEnvManager():
def __init__(self, device):
self.device = device
self.env = gym.make('CartPole-v1').unwrapped
self.env.reset()
self.current_screen = None
self.done = None
def reset(self):
self.env.reset()
self.current_screen = None
def close(self):
self.env.close()
def render(self, mode='human'):
self.env.render_mode = mode
return self.env.render()
def num_actions_available(self):
return self.env.action_space.n
def take_action(self, action):
_, reward, self.done, _, _ = self.env.step(action.item()) # item() coz action will be a tensor
return torch.tensor([reward], device=self.device) # datatype consistence is important
def just_starting(self):
return self.current_screen is None
def get_state(self):
if self.just_starting() or self.done:
self.current_screen = self.get_processed_screen()
black_screen = torch.zeros_like(self.current_screen)
return black_screen
else: # middle of the episode
s1 = self.current_screen
s2 = self.get_processed_screen()
self.current_screen = s2
return s2 - s1
def get_screen_height(self):
screen = self.get_processed_screen()
return screen.shape[2]
def get_screen_width(self):
screen = self.get_processed_screen()
return screen.shape[3]
def get_processed_screen(self):
screen = self.render('rgb_array').transpose((2, 0, 1))
screen = self.crop_screen(screen)
return self.transform_screen_data(screen)
def crop_screen(self, screen):
screen_height = screen.shape[1]
# Strip off top and bottom
top = int(screen_height * 0.4)
bottom = int(screen_height * 0.8)
screen = screen[:, top:bottom, :]
return screen
def transform_screen_data(self, screen):
# Convert to float, rescale, convert to tensor
screen = np.ascontiguousarray(screen, dtype=np.float32) / 255 # convert to float, rescale
screen = torch.from_numpy(screen) # convert to pytorch tensor
# Use torchvision package to compose image transforms
resize = T.Compose([
T.ToPILImage() # first transform to PILImage
, T.Resize((40,90))
, T.ToTensor() # then transform to Tensor
])
return resize(screen).unsqueeze(0).to(self.device) # add a batch dime
2.4 Helper Functions
Plotting,画图,以visualize我们的结果:
def plot(values, moving_avg_period):
plt.figure(2)
plt.clf()
plt.title('Training...')
plt.xlabel('Episode')
plt.ylabel('Duration')
plt.plot(values)
moving_avg = get_moving_average(moving_avg_period, values)
plt.plot(moving_avg)
plt.pause(0.001)
print("Episode", len(values), "\n", \
moving_avg_period, "episode moving avg:", moving_avg[-1])
if is_ipython: display.clear_output(wait=True)
def get_moving_average(period, values):
values = torch.tensor(values, dtype=torch.float)
if len(values) >= period:
moving_avg = values.unfold(dimension=0, size=period, step=1) \
.mean(dim=1).flatten(start_dim=0)
moving_avg = torch.cat((torch.zeros(period-1), moving_avg))
return moving_avg.numpy()
else:
moving_avg = torch.zeros(len(values))
return moving_avg.numpy()
Tensor processing,将我们的Experience处理成tensor进行处理的函数:
def extract_tensors(experience):
batch = Experience(*zip(*experiences))
t1 = torch.cat(batch.state)
t2 = torch.cat(batch.action)
t3 = torch.cat(batch.reward)
t4 = torch.cat(batch.next_state)
return (t1, t2, t3, t4)
Q-Value Calculator,我们获得current state的Q-value 和 next state的Q-value的方法(静态函数):
class QValues():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
@staticmethod
def get_current(policy_net, states, actions):
return policy_net(states).gather(dim=1, index=actions.unsqueeze(-1)) # predicted Q-values
@staticmethod
def get_next(target_net, next_states):
final_state_locations = next_states.flatten(start_dim=1) \
.max(dim=1)[0].eq(0).type(torch.bool) # find a final state
non_final_state_locations = (final_state_locations == False)
non_final_states = next_states[non_final_state_locations]
batch_size = next_states.shape[0]
values = torch.zeros(batch_size).to(QValues.device)
values[non_final_state_locations] = target_net(non_final_states).max(dim=1)[0].detach() # get batch size Q-values
return values
2.5 Main方法
主函数
batch_size = 256
gamma = 0.999 # discount factor in Bellman equation
eps_start = 1 # exploration rate
eps_end = 0.01
eps_decay = 0.001
target_update = 10 # update target network every 10 episodes
memory_size = 100000 # replay memory
lr = 0.001
num_episodes = 1000
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
em = CartPoleEnvManager(device)
strategy = EpsilonGreedyStrategy(eps_start, eps_end, eps_decay)
agent = Agent(strategy, em.num_actions_available(), device)
memory = ReplayMemory(memory_size)
policy_net = DQN(em.get_screen_height(), em.get_screen_width()).to(device)
target_net = DQN(em.get_screen_height(), em.get_screen_width()).to(device)
target_net.load_state_dict(policy_net.state_dict())
target_net.eval() # not a training net, and will only be used for inference
optimizer = optim.Adam(params=policy_net.parameters(), lr=lr)
episode_durations = []
for episode in range(num_episodes):
em.reset()
state = em.get_state()
for timestep in count():
action = agent.select_actions(state, policy_net)
reward = em.take_action(action)
next_state = em.get_state()
memory.push(Experience(state, action, next_state, reward))
state = next_state
if memory.can_provide_sample(batch_size):
experiences = memory.sample(batch_size)
states, actions, rewards, next_states = extract_tensors(experiences)
current_q_values = QValues.get_current(policy_net, states, actions)
next_q_values = QValues.get_next(target_net, next_states)
target_q_values = (next_q_values * gamma) + rewards
loss = F.mse_loss(current_q_values, target_q_values.unsqueeze(1))
optimizer.zero_grad() # otherwise, accumulate gradient at all backward?
loss.backward()
optimizer.step() # update
if em.done:
episode_durations.append(timestep)
plot(episode_durations, 100)
break
if episode % target_update == 0: # update target_net
target_net.load_state_dict(policy_net.state_dict())
em.close()
2.6 结果
我们1000次的结果如下:
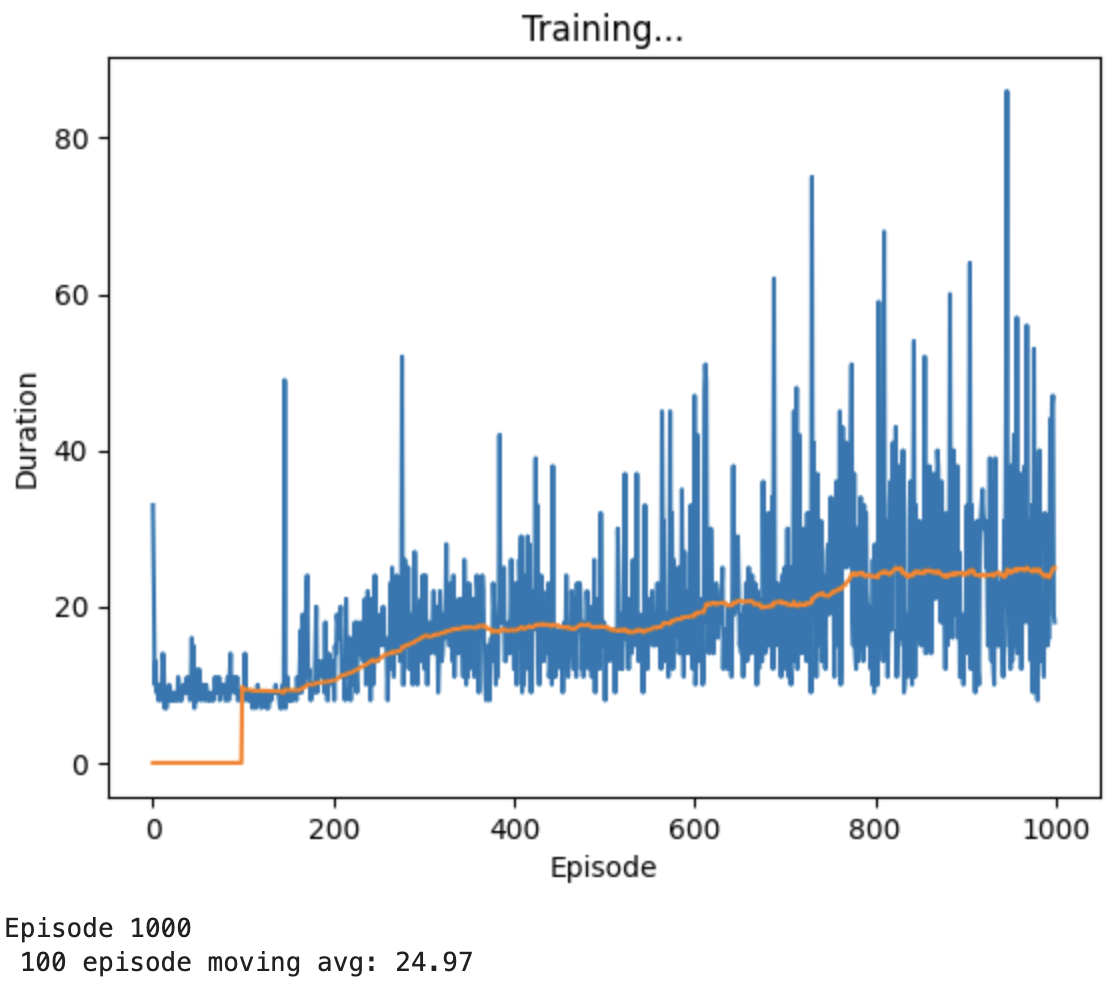
可以看出来我们这一次的Running并没有取得一个很好的结果,可能需要多次重复。虽然相比original而言有所提升,但是与目标值>=195而言相差很远。
我们未来可以采取的方法是:
- 调整参数(Tune hyperparameters)
- 调整网络(Change network architecture)
- 调整算法(Use another algorithm)
- 调整输入/输出的形式,我们这里用的是图片,不一定是图片,也可以是其他类型的data;或者预处理的方法(Change input format/preprocessing)
总结
总之,昨天重新复习了一下Reinforcement Learning, 今天一脚迈进了Deep Reinforcement Learning的大门。
需要学习的东西,还有很多,加油!
今天比较赶时间,要去做饭了,晚上要回比利时。 0.0!
参考
[1] Reinforcement Learning - Developing Intelligent Agents
[2] Cart Pole - Gym Documentation
Q.E.D.