








前言
最近在train模型,用cleverhans进行攻击Projected Gradient Descent攻击,但是不知道为什么一用到L2 normalization的时候,就会出现out of memory的问题,很奇怪。一查issues,发现果然存在GPU leaking的问题,参考来自《cleverhans.torch.utils.clip_eta will cause GPU memory leaking for its in-place operation #1230》
正文
1. 问题所在
查了一下现在的最新版本《cleverhans/cleverhans/torch/utils.py》,发现问题仍然存在,我不明白,其实就是很简单的改一下,但是他就是一直没有改,很奇怪。
位置位于clverhans/clervhans/torch/utils.py 的第38行,hash:574efc1d2f5c7e102c78cf0e937654e847267522。
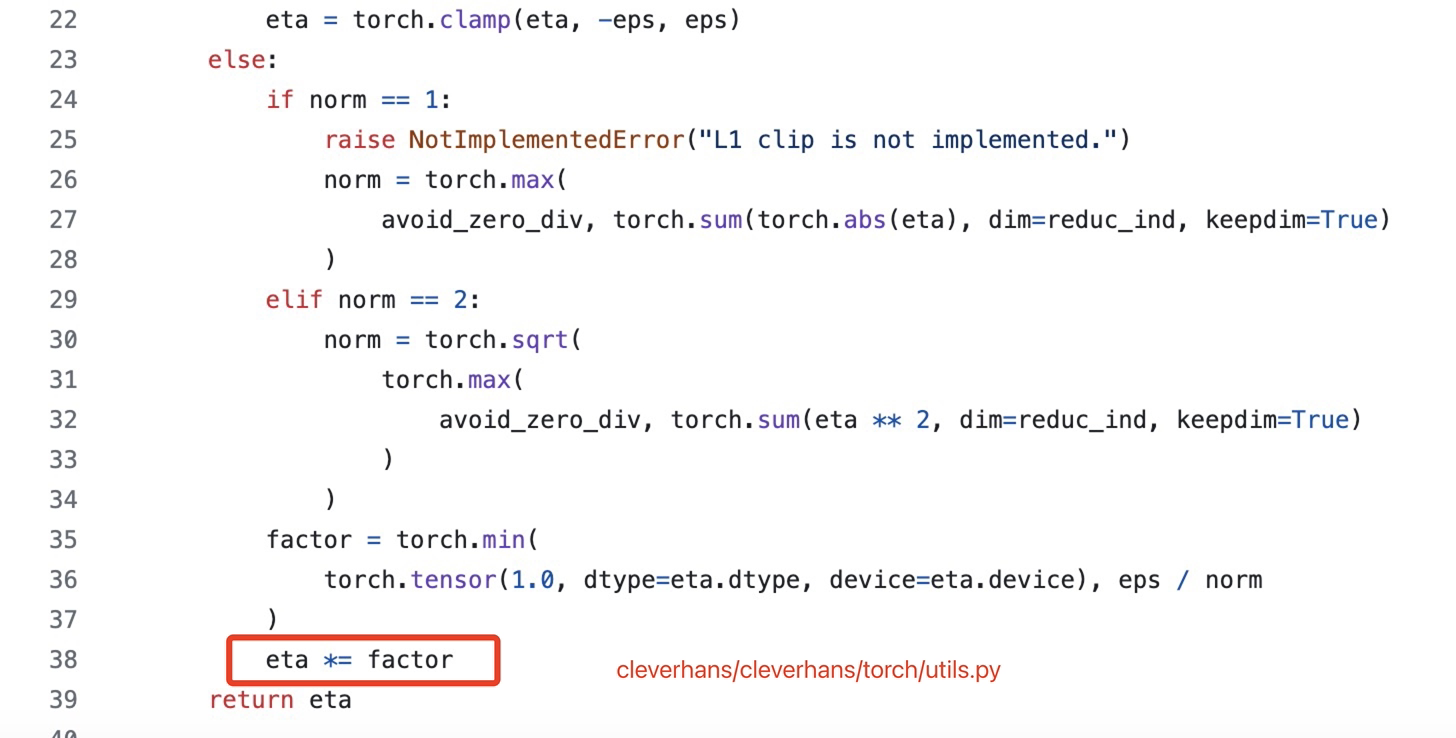
具体的问题其实并不是由于python,而是由于pytorch的机制。如果是正常的非in-place操作,eta = eta * factor, 旧的eta其实是会自动被清除掉;但是由于这里是eta *= factor,pytorch为了保证梯度计算的正确,会保留一个eta的张量副本。如果计算图中的一些张量在计算过程中被多次修改而不释放原来的版本,就会导致内存逐渐增加,最终可能导致内存溢出。
2. 解决办法
避免in-place操作: 将eta *= factor替换为eta = eta * factor即可。这样可以确保每次操作都会生成一个新的张量,而不是修改现有的张量,从而避免潜在的内存问题。
于是乎pip install cleverhans,进入clverhans/clervhans/torch/utils.py,跳到eta *= factor的位置,修改为eta = eta * factor。
成功~!
总结
pytorch的特性~!
谨记:如果计算图中的一些张量在计算过程中被多次修改而不释放原来的版本,就会导致内存逐渐增加,最终可能导致内存溢出。
参考
[1] cleverhans.torch.utils.clip_eta will cause GPU memory leaking for its in-place operation #1230
[2] cleverhans/cleverhans/torch/utils.py
[3] ChatGPT
Q.E.D.