








前言
最近在做Computer Vision的项目,设计一系列的人脸检测问题,刚好看见一片博客写的很好,遂打算在其基础上,继续学习。
但是今天太累了,摸了,明天在写。
2020年4月4日 12:39 am
好了,开工
2022年4月4日 10:08 pm
正文
1. 简要
1.1 从古至今
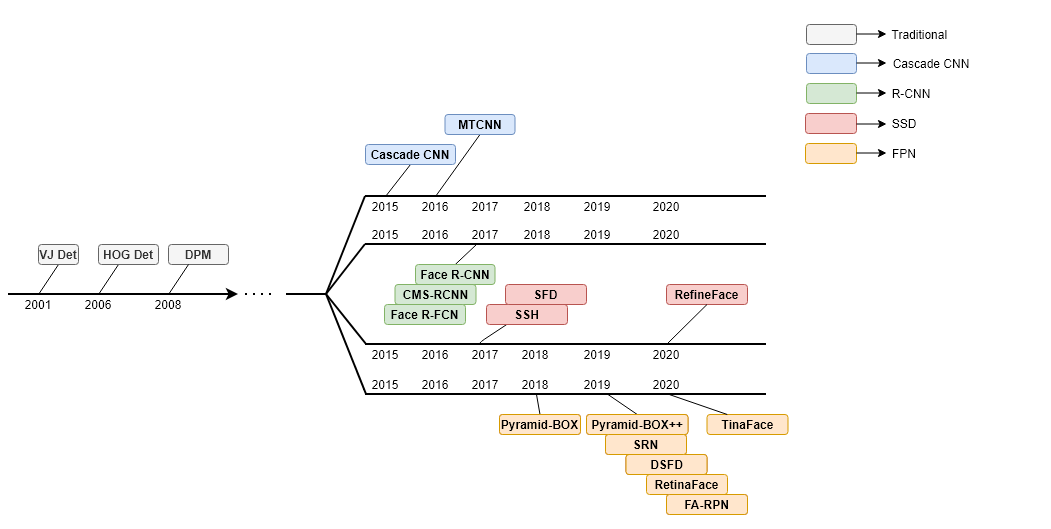
以下大部分都基于人脸检测从传统到深度学习的方法:
从问题的领域来看,人脸检测当前属于目标检测领域,主要分为多目标+背景和特定目标+背景:
- 多分类问题:图像中有多个分类目标。n(目标)+1(背景) = n+1分类
- 特定类别目标检测:人脸检测、行人检测、车辆检测。1(目标)+1(背景)= 2分类
从发展历史来看,人脸检测主要分为非深度学习(传统)和深度学习阶段(现代):
- 非深度学习阶段:主要基于rigid-templates的方法(Haar+AdaBoost分类、LBP+AdaBoost、HOG+SVM)以及基于可变组件模型(Deformable Part Model, DPM)的方法,DPM是深度学习之前最有效的人脸检测算法。
- 深度学习阶段:R-CNN、SSD。
1.2 需要的一些包和Helper
在后续如果有函数function没有实现代码,均在这里可以找到;顺便提供本jupyter notebook下载与引用的packages:
Helper:
# 下载model
def download_model(url, path):
with request.urlopen(url) as r, open(path, 'wb') as f:
f.write(r.read())
Packages:
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# io, os, http, plot, regex helper
from urllib import request # module for opening HTTP requests
from matplotlib import pyplot as plt # Plotting library
from PIL import Image # load image
import io # Input/Output Module
import os # OS interfaces
import re # regular expression
# data manager( e.g., data frame, numpy) helper
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import numpy as np # linear algebra
# computer vision: https://opencv.org
import cv2 # OpenCV package
# pre processor
from mtcnn.mtcnn import MTCNN
# dlib
import dlib
# tensorflow - Keras: https://keras.io
from tensorflow.keras.layers import Conv2D, BatchNormalization, Flatten, Dense, MaxPooling2D # keras NN layers
from tensorflow.keras.preprocessing.image import ImageDataGenerator # Data augmentation
from tensorflow.keras import Model, Input, Sequential # keras NN related
import tensorflow as tf # tensorflow package
# assign GPU
physical_gpus = tf.config.list_physical_devices('GPU') # get current GPU
tf.config.experimental.set_memory_growth(physical_gpus[0], True) # set GPU running method
print('Num GPUs Available', len(physical_gpus)) # see number of available GPU
print(physical_gpus) # print current available GPU
2. 传统阶段
2.1 Haar Cascade Classifier (opencv)
Viola-Jones对象检测框架,是2004年计算机视觉研究者Paul Viola 和 Michael Jones在论文Rapid Object Detection using a Boosted Cascade of Simple Features中提出。他们开发了一个可以实时检测各种物体的框架,但主要的动机为人脸检测,论文中也以人脸检测作为例子展开。
一般来讲,Haar特征级联分类器主要由四部分构成:
- 选择Haar-Like特征
- 创建积分图Integral image
- 训练AdaBoost
- 创建级联分类器
优点:
- 在CPU上可以实时运行
- 简单的结构
- 可以检测不同尺度的人脸
缺点:
- 只能检测正面人脸,侧脸难以检测
- 会有很多错误的检测
- 有遮挡的场景检测效果很差
示例:
我们这里的图片来自日本这所被戏称”看颜值录取”的大学,选出的校花校草得长啥样?,做科研嘛,自然要挑一些舒服的来啦 = -=。原图在下方

具体的Haar Cascade Classifier代码:
# 下载模型
url = "https://raw.githubusercontent.com/opencv/opencv/master/data/"\
"haarcascades/haarcascade_frontalface_default.xml"
download_model(url=url, path='xml/haarcascade_frontalface_default.xml')
# 导入模型
haar_face_cascade=cv2.CascadeClassifier('xml/haarcascade_frontalface_default.xml')
# 导入图片
img = Image.open('img.jpg')
img = np.asarray(img)
print(img.shape)
plt.imshow(img)
plt.title('Image used for learning')
# 检测人脸
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = haar_face_cascade.detectMultiScale(gray, scaleFactor=1.2, minSize=(10,10), maxSize=(200,200))
print("faces number:", len(faces))
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
plt.imshow(img)
# 输出图片
img = Image.fromarray(img)
img.save("pics/learning_haarcascade_frontalface_default.jpg")
图片输出结果:

从结果发现,确实Haar Classifier对于侧脸的识别不尽人意。
2.2 LBP Cascade Classifier (opencv)
LBP (Local Binary Patterns)是纹理描述子,人脸由微纹理图案组成。提取LBP特征,形成特征向量,对人脸和非人脸进行分类。
LBP级联分类器的主要由以下四部分组成:
- LBP Labelling, 图像二值化
- Feature Vector, 图像被划为子区域每个子区域构造一个标签直方图。然后将子区域直方图拼接成一个大直方图,形成一个特征向量
- AdaBoost Learning,利用AdaBoost构造强分类器,取出特征向量中无用的部分
- Cascade Classifier,由上面获得的AdaBoost组成级联分类器。从简单的分类器到强分类器对图像子区域进行评价。如果在该阶段任何一个分类器分类失败,则在该迭代处丢弃。只有面部区域可以通过所有的分类阶段。
优点:
- 计算简单、快速
- 比Haar更短的训练时间
- 对局部照明改变更robust
- 对遮挡场景更robust
缺点:
- 相比Haar准确率更低
- 有比较高的错误检测率
示例:
# 下载模型
url = "https://raw.githubusercontent.com/opencv/opencv/master/data/"\
"lbpcascades/lbpcascade_frontalface.xml"
download_model(url=url, path='xml/lbpcascade_frontalface.xml')
# 导入模型
lbp_face_cascade=cv2.CascadeClassifier('xml/lbpcascade_frontalface.xml')
# 导入图片
img = Image.open('img.jpg')
img = np.asarray(img)
print(img.shape)
plt.imshow(img)
plt.title('Image used for LBP Cascade Classifier')
# 检测人脸
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = lbp_face_cascade.detectMultiScale(gray, scaleFactor=1.2, minSize=(10,10),maxSize=(300,300))
print("faces number:", len(faces))
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
plt.imshow(img)
# 输出图片
img = Image.fromarray(img)
img.save("pics/learning_lbpcascade_frontalface.jpg")
图片输出结果:

我们可以发现,LBP Cascade Classifier的结果确实比Haar Classifier效果要差。
2.3 HOG (dlib) and SVM
方向梯度直方图(Histogram of Oriented Gradient, HOG),是一种全局图像特征描述子(与LBP不同)。它通过计算和统计图像局部区域的直方图来构造特征。基于HOG特征和SVM分类器的人脸检测模型被广泛地使用。
优点:
- 可以很好的检测正脸人脸,和轻度的侧脸
- 在轻度的遮挡场景下也可以使用
缺点:
- 主要的缺点是它不检测小的脸。因为它的训练集中最小的脸是80x80(dlib)。不过,你可以在自己的训练数据上训练HOG人脸检测模型来检测更小的人脸
- 边框往往排除部分额头、甚至有时候会缺少下巴
- 在严重遮挡场景下不能工作
- 不能检测过度侧脸、和极端非正脸(向上或向下看)
示例:
# 导入图片
img = Image.open('img.jpg')
img = np.asarray(img)
print(img.shape)
plt.imshow(img)
plt.title('Image used for HOG Cascade Classifier')
# 导入模型
detector = dlib.get_frontal_face_detector()
# 检测人脸
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(gray, 2) # result
#to draw faces on image
print("faces number:", len(faces))
for result in faces:
x = result.left()
y = result.top()
x1 = result.right()
y1 = result.bottom()
cv2.rectangle(img, (x, y), (x1, y1), (0, 255, 0), 2)
plt.imshow(img)
# 输出图片
img = Image.fromarray(img)
img.save("pics/learning_HOG.jpg")
图片输出结果:
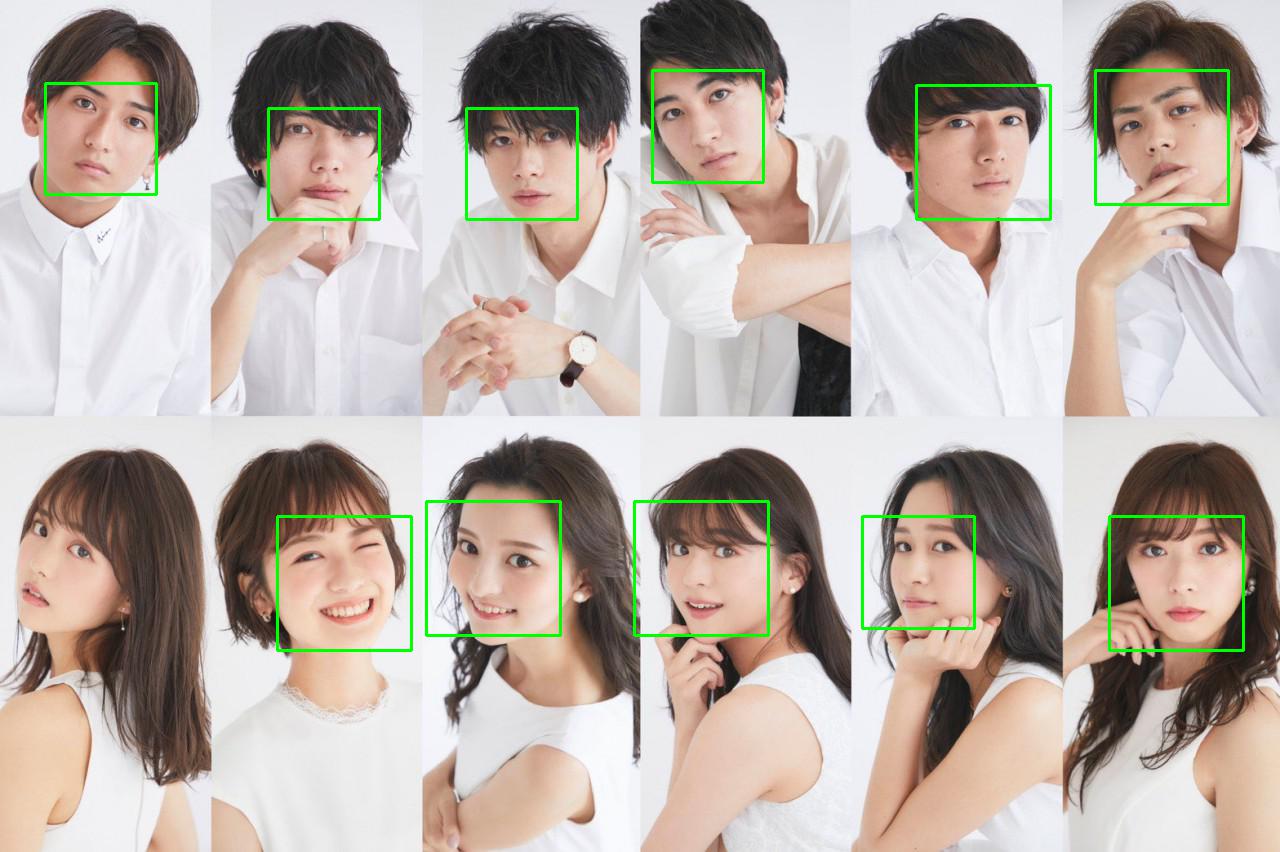
我们发现HOG给的结果,非常的优秀,比Haar和LBP都要优秀得多,基本除了左下角,其余11个人脸都能识别得出来。
3. 深度学习阶段
3.1 MMOD(dlib)
这个方法采用了基于CNN的最大边缘目标检测器(Maximum-Margin Object Detector, MMOD),来自Max-Margin Object Detection。这个model是dlib社区的开发者写的,model可以从Github-davisking/dlib-models/mmod_human_face_detector.dat.bz2下载。它使用了一个作者手工标记的数据集,来自ImageNet、PASCAL VOC、VGG、WIDER等不同数据集的图像组成,它包含了7220个图像,数据集的下载地址:dlib_face_detection_dataset。
优点:
- 适用于不同的面部朝向
- 扛遮挡能力强
- 在GPU上运算很快
缺点:
- 在CPU上运行相当慢(Python Dlib似乎都不支持在GPU??上运行)
- 和HOG一样,不能检测小于80x80的人脸,但是一样的是,你可以在自己的训练数据上训练HOG人脸检测模型来检测更小的人脸
- 边界框甚至比HOG检测器还要小
示例:
# 导入图片
img = Image.open('img.jpg')
img = np.asarray(img)
print(img.shape)
plt.imshow(img)
plt.title('Image used for HOG Cascade Classifier')
# 导入模型,从https://github.com/davisking/dlib-models/blob/master/mmod_human_face_detector.dat.bz2下载
dnnFaceDetector=dlib.cnn_face_detection_model_v1("dat/mmod_human_face_detector.dat")
faceRects = dnnFaceDetector(img, 2)
# 检测人脸
print("faces number:", len(faceRects))
for faceRect in faceRects:
x1 = faceRect.rect.left()
y1 = faceRect.rect.top()
x2 = faceRect.rect.right()
y2 = faceRect.rect.bottom()
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
plt.imshow(img)
# 输出图片
img = Image.fromarray(img)
img.save("pics/learning_MMOD.jpg")
图片输出结果:
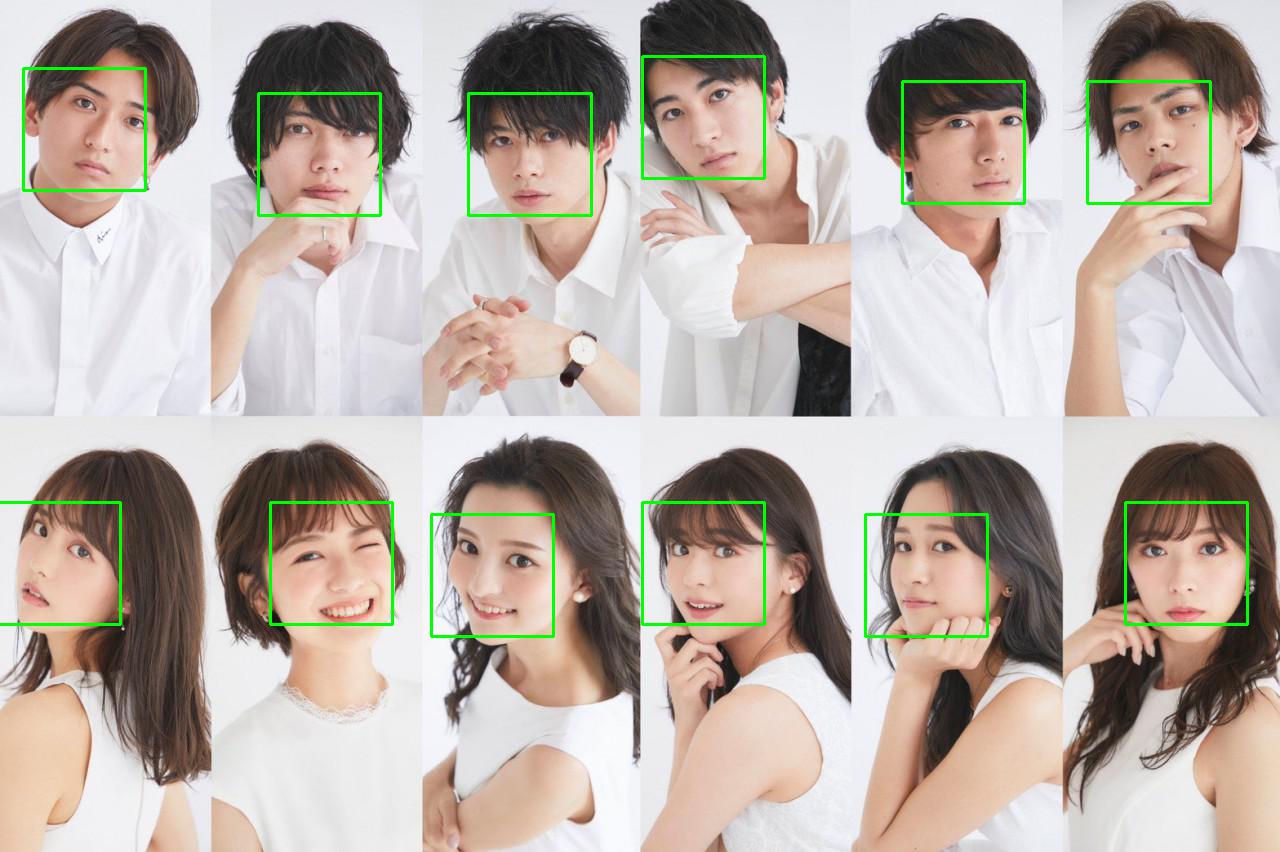
可以看出,深度学习阶段的model,比传统model识别率更高。用了MMOD之后,12个人脸全部都被识别出来了。
3.2 DNN Face (opencv)
在OpenCV3.3版本之后,据博主所说,contrib包含了dnn模块。自然也有了基于DNN的人脸检测模块。基于SSD(Single-Shot-Multibox Detector,来自于SSD: Single Shot MultiBox Detector)并且使用ResNet-10结构作为网络主干。组成model的deploy.prototxt和res10_300x300_ssd_iter_140000.caffemodel文件分别在Gitlab-Java-Exercises9-JavaCV/data找到。
优点:
- 比上述四种方法准确率都高
- 在CPU上也能够实时运行(视CPU性能而定)
- 适用于不同的面部方向(上、下、左、右、侧)
- 适用于严重遮挡场景
- 可以检测不同尺度的人脸
缺点:
- 不支持GPU??为什么作为DL却不支持GPU??
示例:
# 导入图片
img = Image.open('img.jpg')
img = np.asarray(img)
print(img.shape)
plt.imshow(img)
plt.title('Image used for DNN Face Classifier')
# 导入模型
prototxt_path = "dat/deploy.prototxt"
weight_path = "dat/res10_300x300_ssd_iter_140000.caffemodel"
net = cv2.dnn.readNetFromCaffe(prototxt_path, weight_path)
# 检测人脸
(h, w) = img.shape[:2]
blob = cv2.dnn.blobFromImage(img, 1.0, img.shape[:2], [104, 117, 123], False, False)
# Actually, if the size of the output image is set as (300,300), the result could not be good.
# blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0, (300, 300), (104.0, 117.0, 123.0))
print("[INFO] computing object detections...")
net.setInput(blob)
detections = net.forward()
set_confidence = 0.5
face_num = detections[:,:,:,2].reshape(detections.shape[2])
print("face numbers:", face_num[face_num>set_confidence].shape[0])
# loop over the detections
for i in range(0, detections.shape[2]):
# prediction
confidence = detections[0, 0, i, 2]
if confidence > set_confidence:
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
cv2.rectangle(img, (startX, startY), (endX, endY), (0, 255, 0), 2)
plt.imshow(img)
# 输出图片
img = Image.fromarray(img)
img.save("pics/learning_DNN.jpg")
图片输出结果:
-2d41fc8799404607ab9d8c439bd216d0.jpg)
可以看出,效果比MMOD要好,边框范围比MMOD要宽。
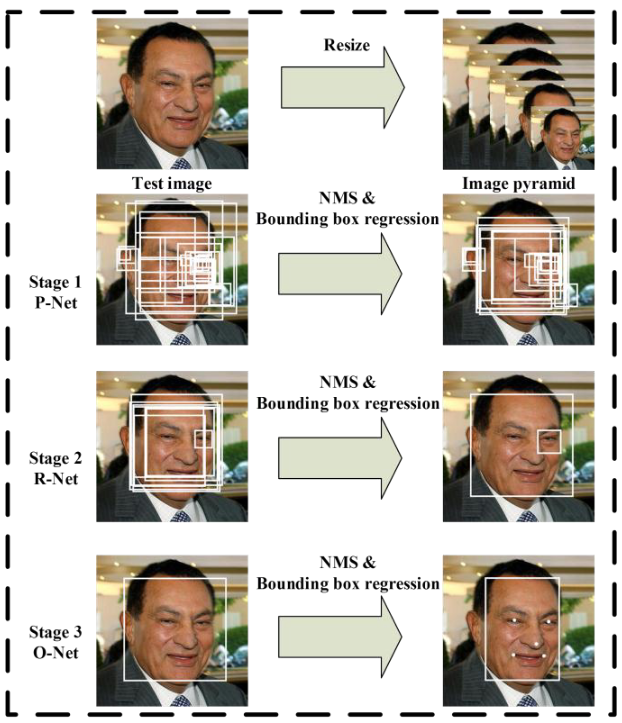
3.3 MTCNN
MTCNN又称(Multi-Task Cascaded Convolutional Networks),于2016年,由Kaipen Zang等人提出的使用多任务级联卷积网络的联合人脸检测和对齐(Joint Face Detection and Alignment using Multi-Task Cascaded Convolutional Networks, MTCNN)一度成为人脸检测最受欢迎的方法之一。MTCNN之所以受欢迎,是因为它在一系列基准数据集上获得了当时最先进的结果,而且除此之外,它还能够识别眼睛、嘴巴、鼻子等其他面部特征。
网络采用三级级联结构,首先将图片重新缩放到不同大小范围(图像金字塔),然后
- 第一个模型P-Net提出候选面部区域
- 第二个模型R-Net过滤边界框
- 第三个模型O-Net提取面部其他特征
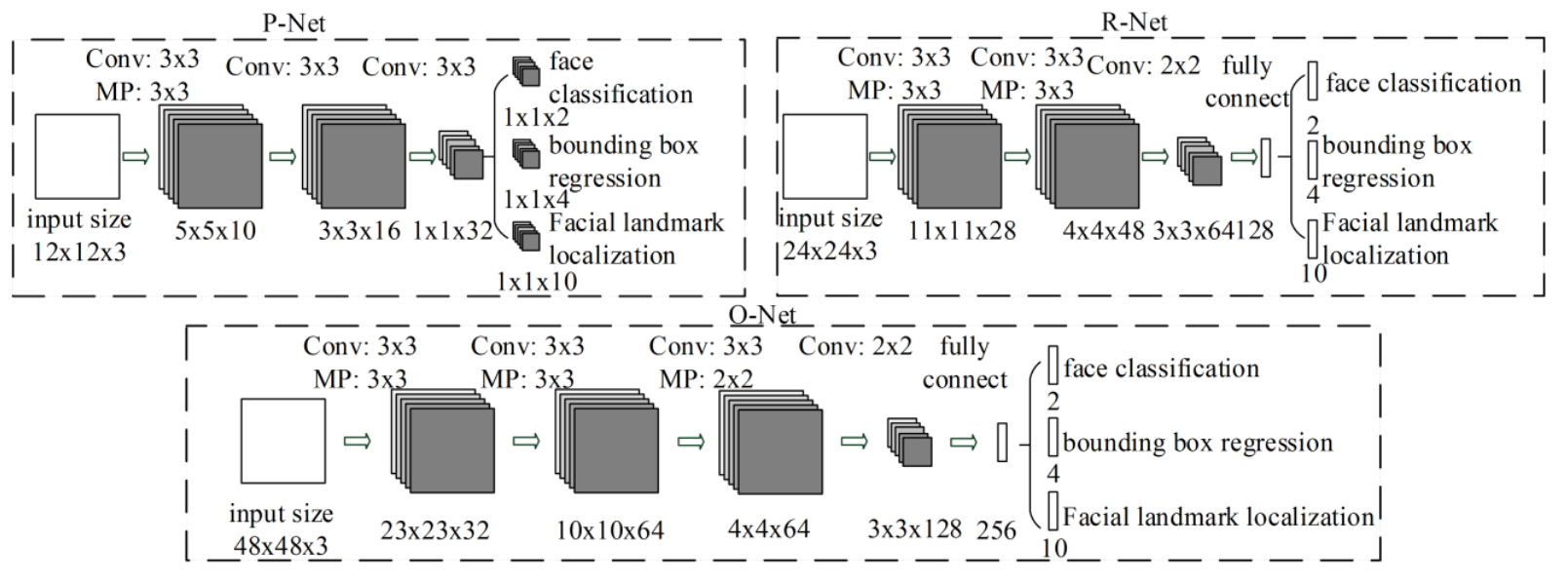
MTCNN主要包含三个阶段
- 通过浅层CNN快速生成候选窗口
- 然后通过更加复杂的CNN对窗口进行挑选、细化
- 最后,使用一个更强大的CNN来细化结果,并且输出面部其他特征位置
示例:
# 导入图片
img = Image.open('img.jpg')
img = np.asarray(img)
print(img.shape)
plt.imshow(img)
plt.title('Image used for MTCNN Face Classifier')
# 导入模型
detector = MTCNN()
rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
faces = detector.detect_faces(rgb)
# 检测人脸
print("face number:", len(faces))
for result in faces:
x, y, w, h = result['box']
keypoints = result['keypoints']
x1, y1 = x + w, y + h
cv2.rectangle(img, (x, y), (x1, y1), (0,255,0), 2)
cv2.circle(img,(keypoints['left_eye']), 2, (0,255,0), 2)
cv2.circle(img,(keypoints['right_eye']), 2, (0,255,0), 2)
plt.imshow(img)
# 输出图片
img = Image.fromarray(img)
img.save("pics/learning_MTCNN.jpg")
图片输出结果:
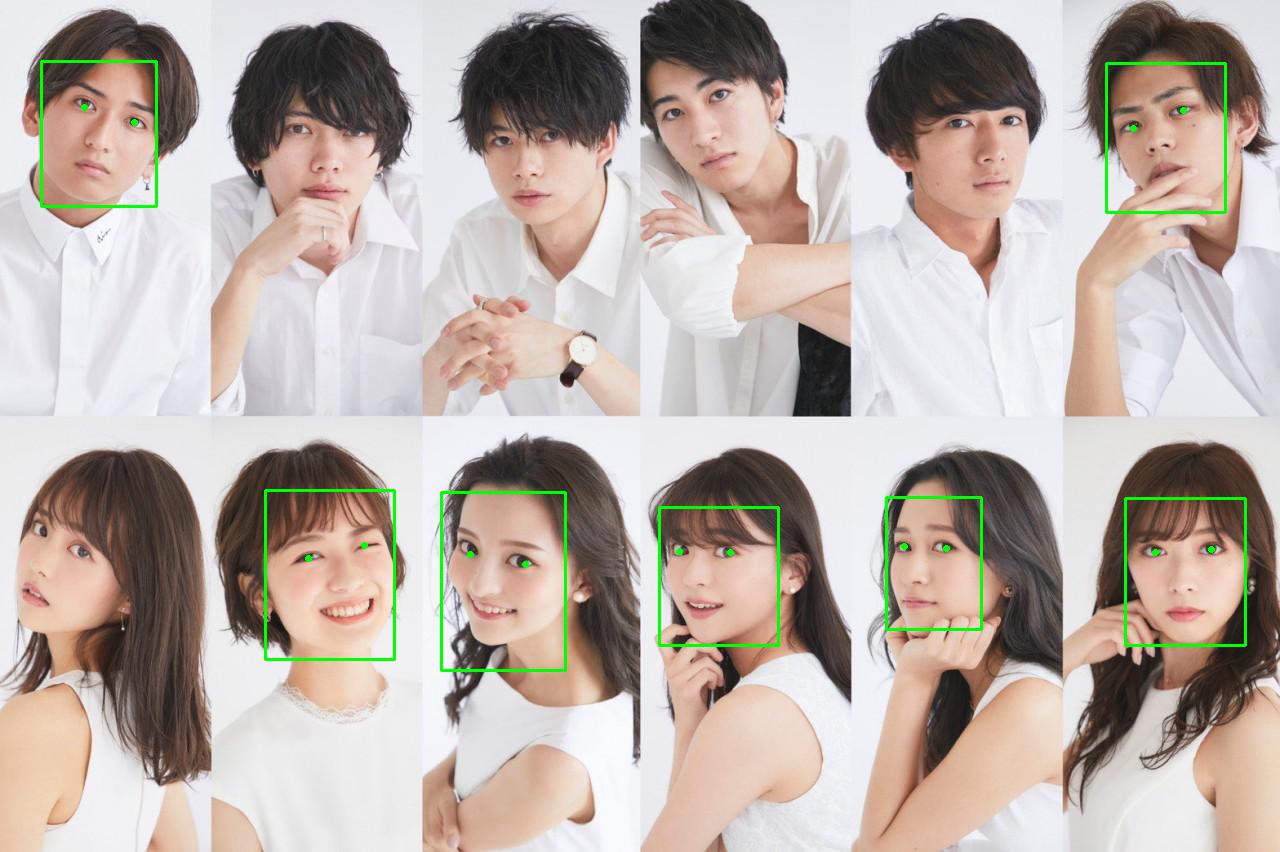
然而由于某些原因,MTCNN并不能完全识别出所有人脸,效果没有DNN、MMOD,甚至传统的HOG好。其原因可以值得深究。
4. Face Detection Benchmark Datasets
4.1 FDDB
FDDB数据集包含2845张图像中的5171张标注人脸。FDDB包含遮挡、不同姿态、低分辨率、失去对焦的人脸,点击此处。

4.2 WIDER FACE
WIDER FACE数据集包含32203张图片中393703张标注人脸。Wider Face数据集基于61个事件类进行组织。对于每个事件类,他们随机选择了40%、10%、50%的数据作为训练、验证和测试集,点击此处。

4.3 MALF
由李子青老师的研究组创立和维护的,包含5250张图片中11931张标注人脸。其性能评估细致,分析不同分辨率、角度、性别、年龄等条件下的算法准确率。除了边界框注释,每个面还包含其他注释,例如:偏航、俯仰和滚转的 姿势变形级别(小、中、大),点击此处。

4.4 UFDD
UFDD包含6425张图像中10897张标注人脸。它涉及雨、雪、阴霾、镜头障碍、模糊、照明变化和干扰物,点击此处。
5. Further Reading
5.1 传统阶段
[Haar]
[1] Traditional Face Detection With Python
[2] 目标检测的图像特征提取之(三)Haar特征
[3] 浅析人脸检测之Haar分类器方法:Haar特征、积分图、 AdaBoost 、级联
[4] 计算机视觉目标检测的框架与过程
[Local Binary Patterns, LBP]
[1] 图像特征提取之LBP特征
[Histogram of Oriented Gradient, HOG]
[1] 目标检测的图像特征提取之(一)HOG特征
[2] 图像的全局特征--HOG特征、DPM特征
[3] Application: A Face Detection Pipeline
[Deep Pyramid Deformable, DPM]
[1] Discriminatively trained deformable part models
[2] ccv
5.2 深度学习阶段
随着2012年神经网络在图像分类中的应用以及受深度学习在计算机视觉领域发展的影响,许多基于深度学习框架的人脸检测方法在过去纪念如雨后春笋般涌现。提出了许多使用不同深度学习架构进行人类检测的方法。为了更好地更全面地总结现有模型,我们将这些模型分为几个突出的类别:
- Cascade-CNN Based Models
- R-CNN Based Models
- Single Shot Detector (SSD) Models
- Feature Pyramid Network Based Models
- Transformers Based Models
- Other Architectures
[Cascade-CNN Based Models]
[1] Zhu, Jun-Yan, et al. "Unpaired image-to-image translation using cycle-consistent adversarial networks." Proceedings of the IEEE international conference on computer vision. 2017.
[2] Li, Haoxiang, et al. "A convolutional neural network cascade for face detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[R-CNN and Faster-RCNN Based Models]
[1] H. Wang, Z. Li, X. Ji, and Y. Wang, “Face r-cnn,” arXiv preprint arXiv:1706.01061, 2017.
[2] Wang, Hao, et al. "Face r-cnn." arXiv preprint arXiv:1706.01061 (2017).
[3] Wang, Yitong, et al. "Detecting faces using region-based fully convolutional networks." arXiv preprint arXiv:1709.05256 (2017).
[SSD based Models]
[1] Najibi, Mahyar, et al. "Ssh: Single stage headless face detector." Proceedings of the IEEE international conference on computer vision. 2017.
[2] Zhang, Shifeng, et al. "S3fd: Single shot scale-invariant face detector." Proceedings of the IEEE international conference on computer vision. 2017.
[3] Zhang, Shifeng, et al. "Refineface: Refinement neural network for high performance face detection." IEEE Transactions on Pattern Analysis and Machine Intelligence (2020).
[Feature Pyramid NetWork Based Models]
[1] Zhang, Jialiang, et al. "Feature agglomeration networks for single stage face detection." Neurocomputing 380 (2020): 180-189.
[2] Tang, Xu, et al. "Pyramidbox: A context-assisted single shot face detector." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[3] Chi, Cheng, et al. "Selective refinement network for high performance face detection." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. No. 01. 2019.
[4] Li, Jian, et al. "DSFD: dual shot face detector." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
[5] Li, Zhihang, et al. "Pyramidbox++: High performance detector for finding tiny face." arXiv preprint arXiv:1904.00386 (2019).
[6] Deng, Jiankang, et al. "Retinaface: Single-stage dense face localisation in the wild." arXiv preprint arXiv:1905.00641 (2019).
[7] Zhu, Yanjia, et al. "TinaFace: Strong but Simple Baseline for Face Detection." arXiv preprint arXiv:2011.13183 (2020).
[Small Summary]
- 基于Cascade-CNN的模型转为高效的高性能人脸检测器而设计,可能适合部署在边缘设备或者相机捕捉应用程序中。然而,这些模型很难在具有低图像素质、非标准姿势和照明的具有挑战性的情况下带来最好的准确性。
- 另一方面,由于使用的模型架构具有更大的容量和学习能力,因此R-CNN等基于通用对象的两阶段检测器会具有更好的检测性。
- SSD等单阶段检测器在精度和效率之间提供了很好的平衡。
- 此外,最近基于Transformer的架构在对象检测方面显示了最先进的结果,并未现有模型的未来扩展提供了潜在的有前途的途径,以将人脸检测的性能提升到一个新的水平。
5.3 其他相关
[Evaluation Metrics]
[1] 准确率(Precision)、召回率(Recall)以及F值(F-Measure)
[Overview]
[1] Going Deeper Into Face Detection: A Survey
[2] A survey on face detection in the wild: Past, present and future
[3] Face Detection: A Survey
[4] 人脸检测算法性能评估、综述及进展
[5] 人脸检测背景介绍和发展现状
参考
[1] 人脸检测从传统到深度学习的方法
Q.E.D.